Learned Impatience
Do people discount delayed reward information relative to immediate reward information, even if the timing of the information has no impact on the delivery of the reward?

Collaborators: David Poensgen, Ian Krajbich
Tools & Languages: Javascript, HTML, CSS, MATLAB, R, stan
Methods: Bayesian Statistics, Experiment Design, Linear and Logistic Mixed Effects Regressions, Model Comparison, Model Simulation and Model Fitting, Reinforcement Learning Models, Sequential Sampling Models, Webcam Eye-tracking
🔭 About
Do people discount delayed reward information relative to immediate reward information, even if the timing of the information has no impact on the delivery of the reward?
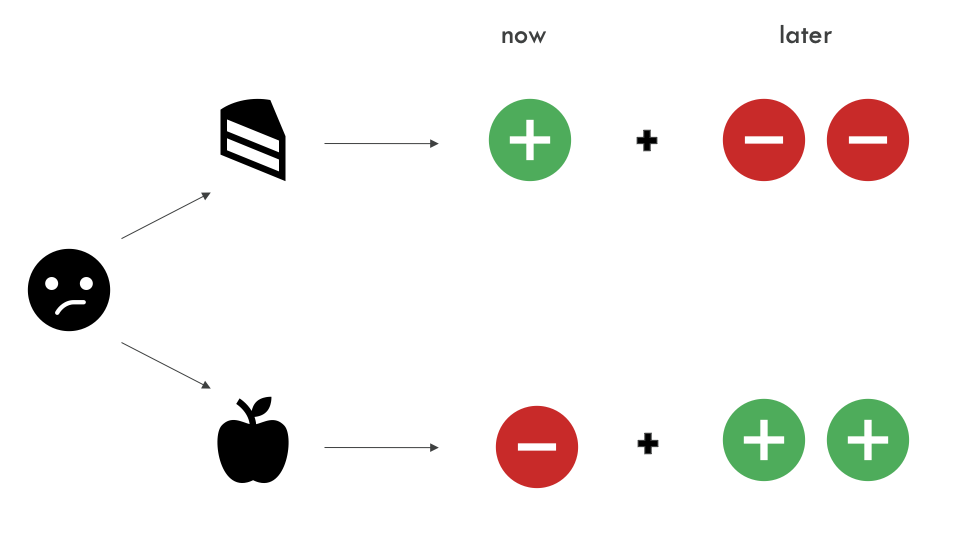
Imagine you’re in a situation where you have to decide which action to take. For instance eat cake ( 🍰 ) or an apple ( 🍎 ).
Usually actions have multiple consequences — some immediate, others delayed.
- If you eat the apple ( 🍎 ) now — it might not be as pleasurable as the cake, but you save some calories from your diet.
- If you eat the cake ( 🍰 ) — you get the small reward now, but you might regret it later.
Next time when you’re in the same situation, you’ll consider what to do based on your previous experience. Will the ordering of the immediate and delayed rewards affect your decision?
Even though in this case, you would be better off choosing the healthy option ( 🍎 ) now since you get a bigger total reward, you might instead choose the unhealthy option ( 🍰 ) because the immediate reward is higher. Then you would be overweighting immediate consequences.
Examples of suboptimal behaviors like this include: overeating, overspending, not working hard enough, exercising too little, not saving enough and so on.
In this project, we study this kind of learning situation in a controlled setting.
👾 Methods
Experimental Design
Study 1 was an in-lab behavioral study; Study 2 was an online webcam eye-tracking study.
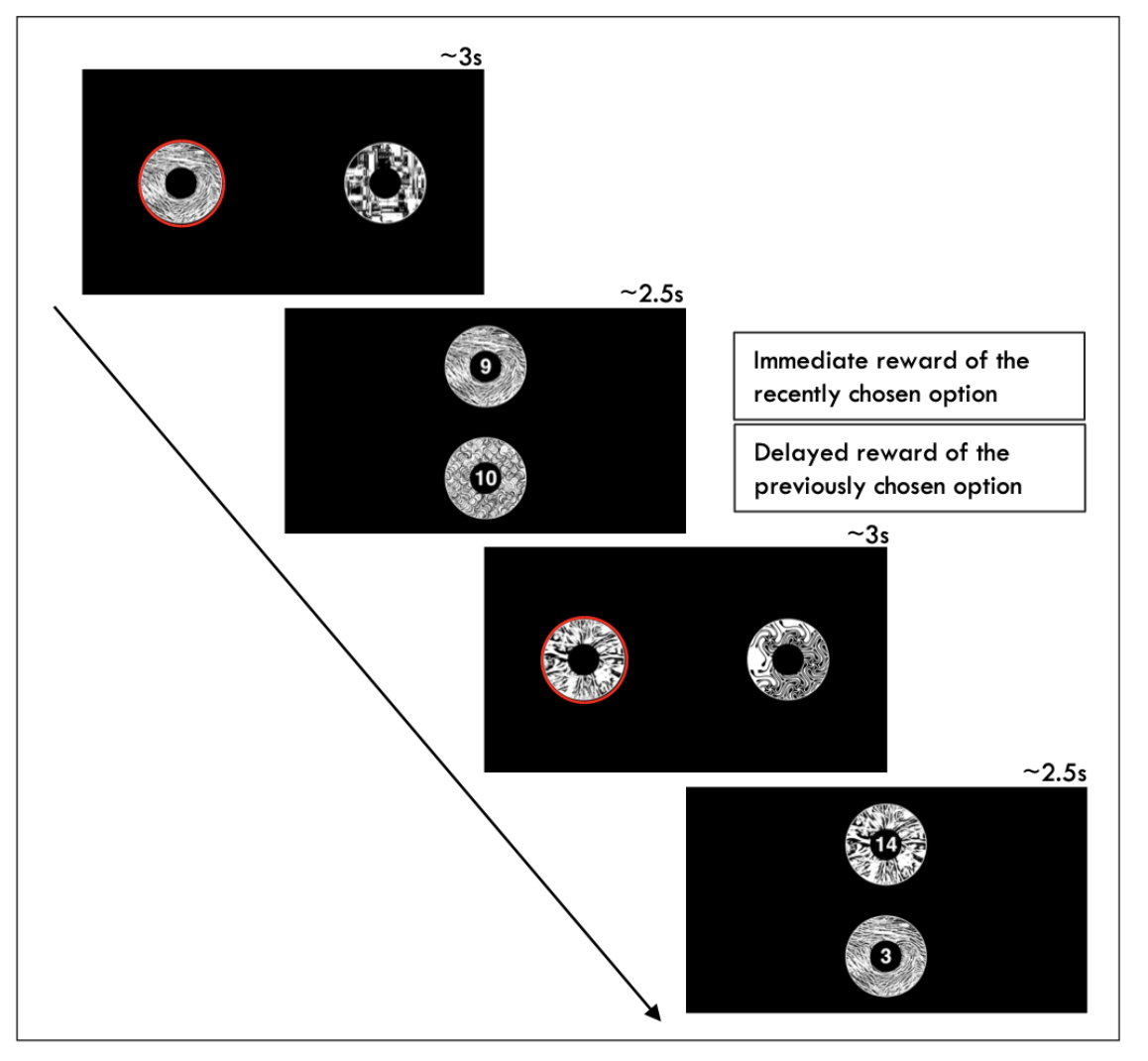
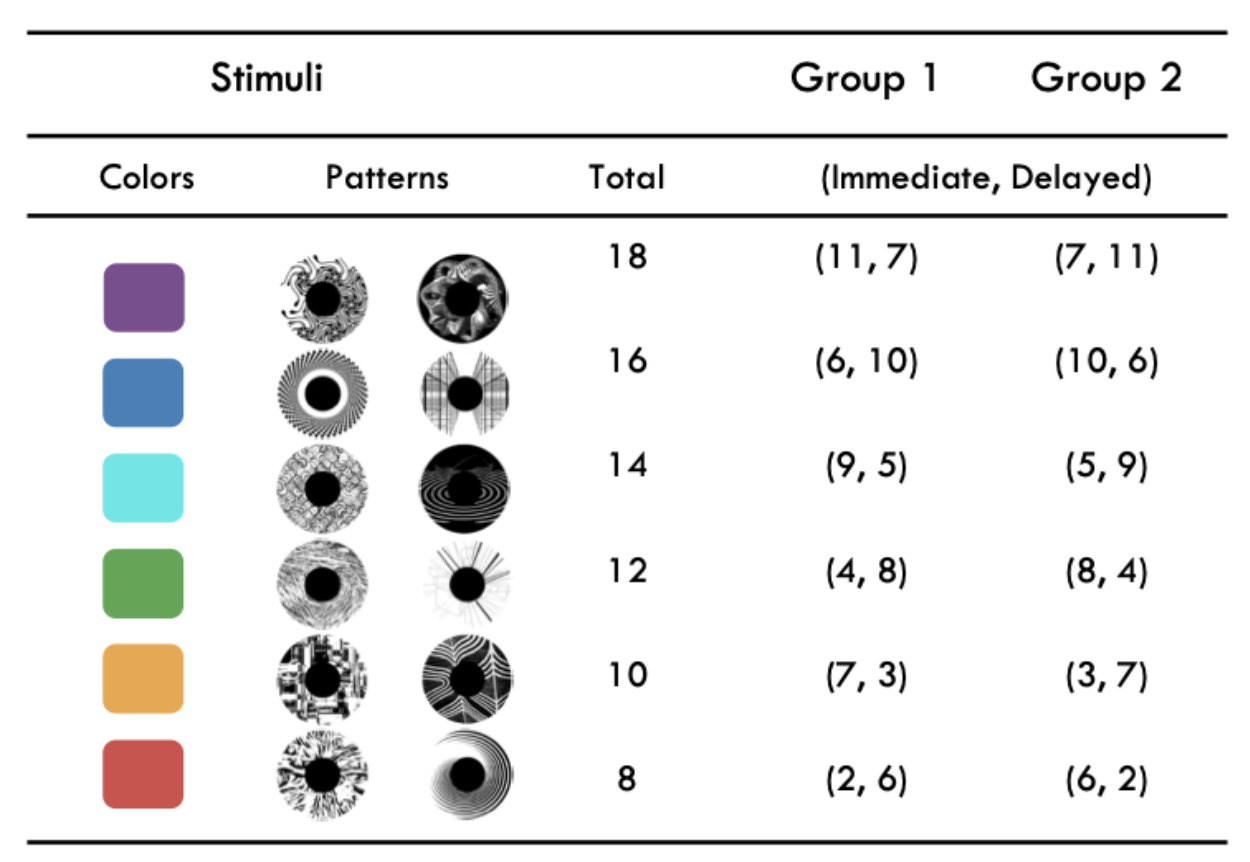
- Stimuli: 6 abstract art images (colors in Study 1, patterns in Study 2)
- Trials: 105 binary choices per subject
- Rewards: each stimulus had an immediate and a delayed reward, plus a small random number drawn from {0, 1, 2, 3} added to each to make learning more difficult
- Option types: rising (immediate < delayed) or falling (immediate > delayed)
- Goal: collect as many points as possible by choosing the stimulus with the highest total payoff
- Potential bias: maximizing immediate rather than total rewards
- Eye-tracking: online webcam eye-tracking using the WebGazer library in jsPsych
Webcam Eye-Tracking
Because data collection took place during the pandemic, we used online webcam eye-tracking. The library was developed by Papoutsaki et al. (2016) and incorporated into jsPsych by Yang and Krajbich (2023). Although precision is much lower than lab eye-tracking, it is useful when showing few stimuli on screen (in this case, 2 images).
Timeline
Subjects first completed a short eye-tracking calibration (excluded if they failed), read the instructions, answered comprehension questions, completed a longer calibration, went through the task, and finished with memory surveys. Additional eye-tracking validations were run during the task; subjects who failed 2 out of 4 were excluded from the eye-tracking analysis.

Sample Size
226 subjects learned the values associated with 6 stimuli: colors in Study 1 (N = 102) and patterns in Study 2 (N = 124).
🏁 Conclusions
We found that subjects overweighted immediate reward information. Moreover, this bias increased over the course of the experiment and was still present when learning from others’ choices.
The gaze data reveal mixed evidence that subjects looked more at immediate vs. delayed feedback, and across subjects, the relative dwell proportion did not predict the behavioral bias.
Our results indicate that people prioritize not just immediate rewards, but immediate reward information. Unlike temporal discounting, this form of impatience is a clear mistake and leads to objectively worse outcomes.
You can read more about it in the paper.